
Note: This is a live draft for an ongoing personal research project. I keep on modifying and adding to this post every week. Any suggestions/modifications in the comments section would be appreciated.
Table of Contents
- Note: This is a live draft for an ongoing personal research project. I keep on modifying and adding to this post every week. Any suggestions/modifications in the comments section would be appreciated.
- What is an Autoencoder? What does it “Auto-Encode”?
- What is the difference between Autoencoders and PCA for Dimensionality reduction?
- Types of Autoencoders
What is an Autoencoder? What does it “Auto-Encode”?

In machine learning, Autoencoding is reducing the dimensions of the dataset while learning how to ignore noise. An Autoencoder is a unsupervised artificial neural network used for learning.
What does it learn? It learns how to compress data then reconstructing it back to a representation close to the original form.
What is an example of an Autoencoder? How does it work?
Autoencoders can be used for various reasons but mostly fall under the umbrella of dimensionality reduction, or feature selection and extraction.
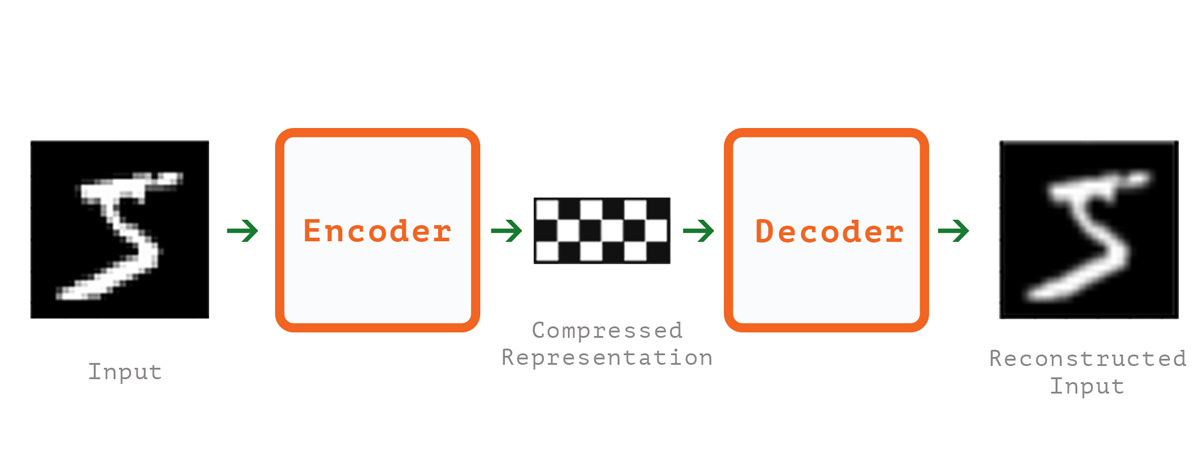
The most famous example for Autonencoding in literature is encoding images from the MNIST dataset:
This process mainly works in 4 steps:
-
Encoding: The model learns how to compress the input into a smaller representation by reducing its dimensions.
-
Bottleneck: This is the part of the network with the least number of nodes. It contains the compressed version of the data.
-
Decoder: Here the model learns how to reconstruct the “close representation” of the original data.
-
(The extra step) Reconstruction: At this step we attempt to calculate the Reconstruction loss, which is how different the reconstructed representation from the original data. In other words, we measure how well did the previous steps work.

Applications
One popular application of autoencoding is Data denoising, which is part to what we did in the MNIST example. You can find more about it here.
Another application is Dimensionality reduction. Working with high dimensional data presents lots of challenges, one of which is visualization. Autoencoders are usually used as a preprocessing stage to visualization methods such as t-SNE.
What is the difference between Autoencoders and PCA for Dimensionality reduction?
-
Non-linear transformations
From a simplistic view, an autoencoder can be similar to PCA, as training an autoencoder with one dense encoder layer and one dense decoder layer and linear activation is similar to performing PCA. However, one major difference is that Autoencoders are capable of learning non-linear transformations using several layers and a non-linear activation function, while PCA falls short on that aspect.
-
Fitting in with other Nets
You can use other pretrained layers from other Neural Networks as input to an autoencoder.
-
Efficiency (?)
When it comes to model parameters, learning using an autoencoder with multiple layers can be more efficient than having one gigantic PCA transformation. This highly depends on the data and the model goal.
-
Data type
Autoencoders perform much better with video/audio and series data as it doesn’t really have to include a huge number of layers to process the data. Autoencoders can learn using convolutional layers.
-
Applicability and Ease of use
If the hidden layer in the autoencoder has higher dimensionality than input data, it may be that the neural net is not actually performing dimensionality reduction. It is simply doing a transformation from one feature space to another.
Ignoring the title of this post for a moment 😃, Autoencoding is a PhD topic, it is an umbrella term that includes a whole let of complex models that I don’t really understand and even if I did it will never be in one post. Applying PCA can easily be the right step to take for your model in terms of how it performs, and in terms of project management, and shipping to production.
Types of Autoencoders
Sparse Encoders
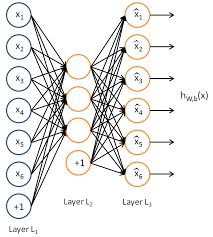
The compressed data in the bottleneck mentioned earlier is also called a code dictionary, and it contains code words. A Sparse autoencoder makes use of a sparsity enforcer to do two things:
- Limit the number of code words (in the hidden layer)
- Minimize the error AKA reconstruction loss.
A sparse encoder has only one single hidden layer connected from both sides by weighted matrices to the input/output (encoder/decoder).
A sparse autoencoder on steroids would be the k-sparse autoencoder, in which we use ReLU activation functions to try to obtain the best sparsity level by optimizing the the number of nodes with the highest activation functions. This number is called k. We do so by adjusting the threshold of ReLU to optimize for k.
Stacked Encoders

The stacked variant of the an Autoencoder is a collection of layered sparse Autoencoders connected to each other; in which each layer is connected to the following layer.
While each layer uses unsupervised learning algorithm, it does get fine tuned using a supervised method. This procedure is carried out as the following:
- First autonecoder is trained and outputs the learned (reconstructed) data.
- The successive (second) layer gets its input from that first layer output.
- This handing over of output->input continues till the end of the network.
- Once all layers are trained, backpropagation is used to reconfigure the weights and do cost minimization.
This kind of stacking of neural networks is what we call deep learning. It has very many promising results, especially in the medical field including brain-computer interfaces.
To be continued…